Métodos
numéricos.
Definición:
Parámetro: Medida descriptiva calculada a partir
de los datos de la población (Usamos letras griegas para denotarlos m, s, r, etc.).
Estadísticas: Medidas descriptivas
calculadas únicamente a partir de los datos muestrales.
Medidas
de Posición
Media: Media aritmética del conjunto de
observaciones.
Media poblacional: Sea x1, x 2, ....., x N el conjunto de datos poblacionales ( N
es el
tamaño de la población) entonces se
define la media poblacional como
Media
muestral: Sea x1, x 2, ....., x n el conjunto de datos muestrales (N es
el tamaño de la muestra) entonces se define la media muestral como
Mediana
muestral: La mediana muestral
de un conjunto de n observaciones x1,
x 2, ... xn es el valor de x tal que a lo sumo el 50% de
las observaciones es menor que x y a lo sumo el 50% de las observaciones es
superior a x. (La mediana poblacional se define de manera similar).
La mediana es menos sensible que la
media a observaciones extremas.
Si x (1), x (2), ....., x
(n) representa el conjunto de observaciones
ordenadas de menor a mayor entonces: a) si n es impar, x Md es la observación central ,x Md = x (x+1) /2 , b)si n es par, x Md es el promedio de las dos observaciones
centrales
x Md =(xn/2 + xn/d+1)/2.
Moda
o modo: El modo de un conjunto
de n observaciones x 1 , x
2 , ....., x n es el
valor de x que ocurre con mayor frecuencia.
Fractiles:
Cuartiles:
Primer
cuartil o cuartil inferior: El valor de x tal que a lo sumo 1/4 de
las observaciones son menores que x y a lo sumo 3/4 son mayores que x.(Q1 =
x.25(n+1) )
Tercer
cuartil o cuartil superior: El valor de x tal que a lo sumo 3/4 de
las observaciones son menores que x y a lo sumo 1/4 son mayores que x.(Q3 =
x.75(n+1) )
Percentiles
Si x (1), x (2), ....., x (n) representa el conjunto de observaciones
ordenadas de menor a mayor del percentil 100p es el valor de x tal que a lo
sumo 100p% de las observaciones son menores x y a lo sumo 100(1- p)% de las
observaciones son mayores que x.
(xpx = x p(n+1) )
Tanto en percentiles como en los
percentiles cuando p(n+1) ( o .25(n+1) o .75(n+1) respectivamente) no es un
entero se debe interpolar o promediar las dos observaciones adyacentes.
Medidas
de dispersión o variabilidad
Rango: El rango de un conjunto de observaciones
x 1 , x 2 , ....., x
n es la diferencia entre la
observación máxima y la mínima, rango = x (n) - x (1)
Varianza
poblacional: Sea x 1 , x 2 , ....., x n el conjunto de datos poblacionales (N
es el tamaño de la población)
Varianza
muestral: Sea x 1 , x 2 , ....., x n el conjunto de datos muestrales (n es
el tamaño de la muestra)
La raíz cuadrada de la varianza se
define como el desvío estándar y está expresada en las mismas unidades que x.
¿QUÉ ES EL ANÁLISIS EXPLORATORIO DE DATOS?
El Análisis Exploratorio de Datos (A.E.D.) es un conjunto de técnicas estadísticas
cuya finalidad es conseguir un entendimiento básico de los datos y de las relaciones
existentes entre las variables analizadas. Para conseguir este objetivo el A.E.D. proporciona
métodos sistemáticos sencillos para organizar y preparar los datos, detectar fallos en el
diseño y recogida de los mismos, tratamiento y evaluación de datos ausentes (missing),
identificación de casos atípicos (outliers) y comprobación de los supuestos subyacentes en
la mayor parte de las técnicas multivariantes (normalidad, linealidad, homocedasticidad).
El examen previo de los datos es un paso necesario, que lleva tiempo, y que
habitualmente se descuida por parte de los analistas de datos. Las tareas implícitas en dicho
examen pueden parecer insignificantes y sin consecuencias a primera vista, pero son una
parte esencial de cualquier análisis estadístico.
ETAPAS DEL A.E.D.
Para realizar un A.E.D. conviene seguir las siguientes etapas:
1) Preparar los datos para hacerlos accesibles a cualquier técnica estadística.
2) Realizar un examen gráfico de la naturaleza de las variables individuales a
analizar y un análisis descriptivo numérico que permita cuantificar algunos
aspectos gráficos de los datos.
3) Realizar un examen gráfico de las relaciones entre las variables analizadas y un
análisis descriptivo numérico que cuantifique el grado de interrelación existente
entre ellas.
4) Evaluar, si fuera necesario, algunos supuestos básicos subyacentes a muchas
técnicas estadísticas como, por ejemplo, la normalidad, linealidad y
homocedasticidad.
5) Identificar los posibles casos atípicos (outliers) y evaluar el impacto potencial que
puedan ejercer en análisis estadísticos posteriores.
6) Evaluar, si fuera necesario, el impacto potencial que pueden tener los datos
ausentes (missing) sobre la representatividad de los datos analizados.
Media ponderada
Es una Medida de
Central o Medida de Posición Central, que se determina en un conjunto de
números al resultado de multiplicar cada uno de los números por un valor
particular para cada uno de ellos, llamado su peso, y obteniendo a continuación
la media aritmética del conjunto formado por los productos anteriores. Se utiliza
la media ponderada cuando no todos los elementos componentes de los que se
pretende obtener la media tienen la misma importancia.
Para una serie de datos

a la que corresponden los pesos

la media ponderada se calcula como:
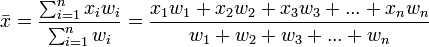
Un
ejemplo es la obtención de la media ponderada de las notas de en
la que se asigna distinta importancia (peso) a cada una de las pruebas de que consta el
examen, entonces se multiplicaría cada nota por su correspondiente peso y el
resultado obtenido se divide entre la suma de los pesos asignados
.
 La distribución hipergeométrica suele
aparecer en procesos muestrales sin remplazo, en los que se investiga la
presencia o ausencia de cierta característica. Piénsese, por ejemplo, en un procedimiento
de control de calidad en una empresa farmacéutica, durante el cual se extraen muestras
de las cápsulas fabricadas y se someten a análisis para determinar su
composición. Durante las pruebas, las cápsulas son destruidas y no pueden ser
devueltas al lote del que provienen. En esta situación, la variable que cuenta
el número de cápsulas que no cumplen los criterios de calidad establecidos
sigue una distribución hipergeométrica. Por tanto, esta distribución es la
equivalente a la binomial, pero cuando el muestreo se hace sin remplazo. Esta
distribución se puede ilustrar del modo siguiente: se tiene una población
finita con N
La distribución hipergeométrica suele
aparecer en procesos muestrales sin remplazo, en los que se investiga la
presencia o ausencia de cierta característica. Piénsese, por ejemplo, en un procedimiento
de control de calidad en una empresa farmacéutica, durante el cual se extraen muestras
de las cápsulas fabricadas y se someten a análisis para determinar su
composición. Durante las pruebas, las cápsulas son destruidas y no pueden ser
devueltas al lote del que provienen. En esta situación, la variable que cuenta
el número de cápsulas que no cumplen los criterios de calidad establecidos
sigue una distribución hipergeométrica. Por tanto, esta distribución es la
equivalente a la binomial, pero cuando el muestreo se hace sin remplazo. Esta
distribución se puede ilustrar del modo siguiente: se tiene una población
finita con N x: max{0,n-(N-R)}, ..., min{R,n}, donde max{0,n-(N-R)}
indica el valor máximo entre 0 y n-
x: max{0,n-(N-R)}, ..., min{R,n}, donde max{0,n-(N-R)}
indica el valor máximo entre 0 y n-

















